|
I am a PhD student in Machine Learning at Université de Montréal and Mila, advised by Guy Wolf in the RAFALES lab and Liam Paull in the Robotics and Embodied AI Lab (REAL) lab. I primarly research scene representations for embodied AI and more generally robot learning, and previously had the chance to work on those topics as an intern at Samsung's SAIT AI Lab (SAIL) and at Nokia Bell Labs. I am currently doing an internship at Apple. |

|
|
|
|
|
||
|
Here are some of my papers. My CV and Google Scholar page include all publications. |
||

|
Sacha Morin, Moonsub Byeon, Alexia Jolicoeur-Martineau, Sébastien Lachapelle [Conference] ICML, 2026 |
|
|
|
||

|
Sacha Morin, Kumaraditya Gupta, Mahtab Sandhu, Charlie Gauthier, Francesco Argenziano, Kirsty Ellis, Liam Paull [Conference] IROS, 2026 [Workshop] NeurIPS 2025 Workshop on Space in Vision, Language, and Embodied AI (SpaVLE), 2025 |
|
|
|
||
|
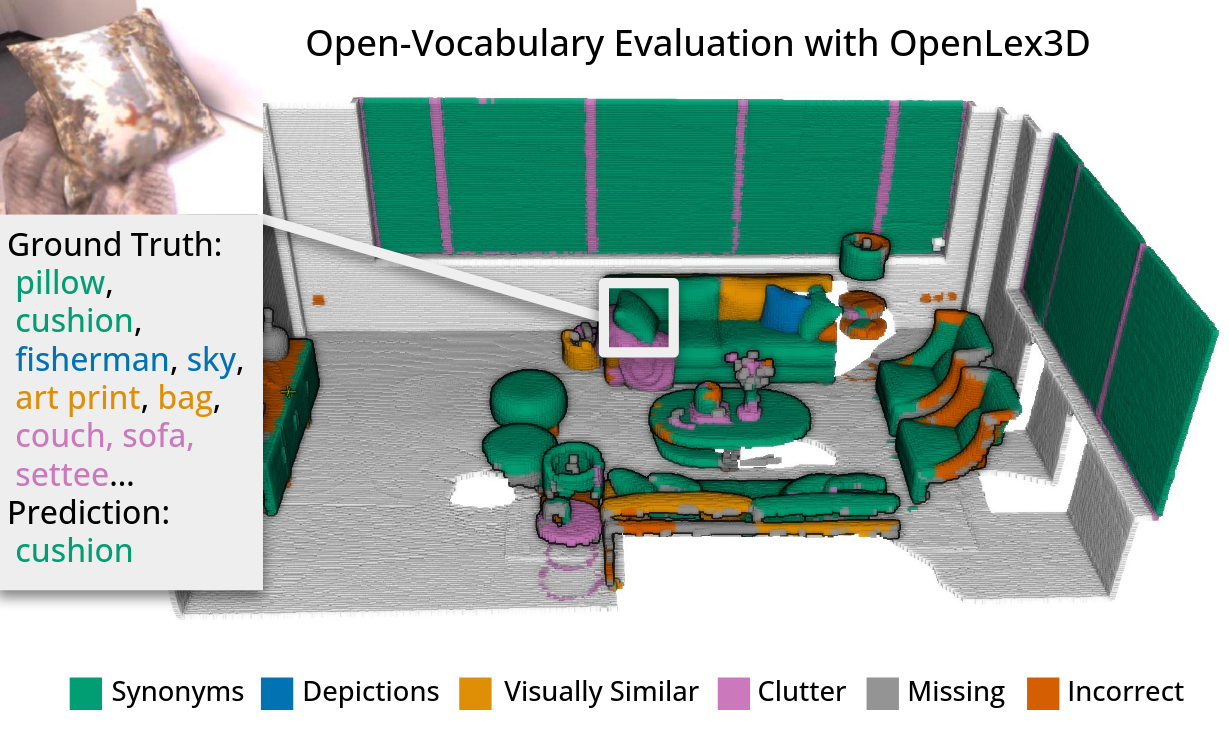
Sacha Morin *, Christina Kassab *, Martin Büchner *, Matias Mattamala, Kumaraditya Gupta, Abhinav Valada, Liam Paull, Maurice Fallon [Conference] NeurIPS Datasets and Benchmarks, 2025 A new dataset and benchmark for dense and object-centric open-vocabulary 3D maps.
3D scene understanding has been transformed by open-vocabulary
language models that enable interaction via natural language. However,
the evaluation of these representations is limited to closed-set
semantics that do not capture the richness of language. This work
presents OpenLex3D, a dedicated benchmark to evaluate 3D open-vocabulary
scene representations. OpenLex3D provides entirely new label annotations
for 23 scenes from Replica, ScanNet++, and HM3D, which capture real-world
linguistic variability by introducing synonymical object categories and
additional nuanced descriptions. By introducing an open-set 3D semantic
segmentation task and an object retrieval task, we provide insights on
feature precision, segmentation, and downstream capabilities. We evaluate various
existing 3D open-vocabulary methods on OpenLex3D, showcasing failure cases, and
avenues for improvement.
|
|
|
|
||

|
Liam Paull, Sacha Morin, Dominic Maggio, Martin Büchner, Cesar Cadena, Abhinav Valada, Luca Carlone [Book Chapter] Cambridge University Press, 2025 |
|
|
|
||

|
Sacha Morin *, Qiao Gu *, Alihusein Kuwajerwala *, Krishna Murthy Jatavallabhula *, Bipasha Sen, Aditya Agarwal, Corban Rivera, William Paul, Kirsty Ellis, Rama Chellappa, Chuang Gan, Celso Miguel de Melo, Joshua B. Tenenbaum, Antonio Torralba, Florian Shkurti, Liam Paull [Conference] ICRA, 2024 Open-vocabulary 3D scene graphs using CLIP features and language captions for semantics.
For robots to perform a wide variety of tasks, they require a 3D representation
of the world that is semantically rich, yet compact and efficient for task-driven
perception and planning. Recent approaches have attempted to leverage features from
large vision-language models to encode semantics in 3D representations. However,
these approaches tend to produce maps with per-point feature vectors, which do not
scale well in larger environments, nor do they contain semantic spatial relationships
between entities in the environment, which are useful for downstream planning.
In this work, we propose ConceptGraphs, an open-vocabulary graph-structured
representation for 3D scenes. ConceptGraphs is built by leveraging 2D foundation models
and fusing their output to 3D by multi-view association. The resulting representations
generalize to novel semantic classes, without the need to collect large 3D datasets or
finetune models. We demonstrate the utility of this representation through a number of
downstream planning tasks that are specified through abstract (language) prompts and
require complex reasoning over spatial and semantic concepts.
|
|
|
|
||

|
Sacha Morin *, Miguel Saavedra-Ruiz *, Liam Paull [Conference] IROS, 2023
code /
arXiv /
webpage /
bibtex
@article{morin2023one,
title = {One-4-All: Neural Potential Fields for Embodied Navigation},
author = {Morin, Sacha and Saavedra-Ruiz, Miguel and Paull, Liam},
year = 2023,
journal = {arXiv preprint arXiv:2303.04011}
}
Image-goal navigation in latent space.
A fundamental task in robotics is to navigate between two locations.
In particular, real-world navigation can require long-horizon planning
using high-dimensional RGB images, which poses a substantial challenge
for end-to-end learning-based approaches. Current semi-parametric methods
instead achieve long-horizon navigation by combining learned modules with
a topological memory of the environment, often represented as a graph over
previously collected images. However, using these graphs in practice typically
involves tuning a number of pruning heuristics to avoid spurious edges, limit
runtime memory usage and allow reasonably fast graph queries. In this work,
we present One-4-All (O4A), a method leveraging self-supervised and manifold
learning to obtain a graph-free, end-to-end navigation pipeline in which the
goal is specified as an image. Navigation is achieved by greedily minimizing
a potential function defined continuously over the O4A latent space. Our system
is trained offline on non-expert exploration sequences of RGB data and controls,
and does not require any depth or pose measurements. We show that O4A can reach
long-range goals in 8 simulated Gibson indoor environments, and further demonstrate
successful real-world navigation using a Jackal UGV platform.
|
|
|
|
||

|
Sacha Morin *, Andres F. Duque *, Guy Wolf, Kevin R. Moon [Journal] IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022
code /
paper /
webpage /
bibtex
@article{duque2022geometry,
title={Geometry Regularized Autoencoders},
author={Duque, Andres F and Morin, Sacha and Wolf, Guy and Moon, Kevin R},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2022},
publisher={IEEE}
}
Manifold-based regularization for learning better representations in autoencoders.
A fundamental task in data exploration is to extract simplified
low dimensional representations that capture intrinsic geometry
in data, especially for faithfully visualizing data in two or
three dimensions. Common approaches to this task use kernel methods
for manifold learning. However, these methods typically only provide an
embedding of fixed input data and cannot extend to new data points.
Autoencoders have also recently become popular for representation
learning. But while they naturally compute feature extractors that
are both extendable to new data and invertible (i.e., reconstructing
original features from latent representation), they have limited capabilities
to follow global intrinsic geometry compared to kernel-based manifold learning.
We present a new method for integrating both approaches by incorporating a
geometric regularization term in the bottleneck of the autoencoder. Our
regularization, based on the diffusion potential distances from the
recently-proposed PHATE visualization method, encourages the learned latent
representation to follow intrinsic data geometry, similar to manifold learning
algorithms, while still enabling faithful extension to new data and reconstruction
of data in the original feature space from latent coordinates. We compare our
approach with leading kernel methods and autoencoder models for manifold learning
to provide qualitative and quantitative evidence of our advantages in preserving
intrinsic structure, out of sample extension, and reconstruction. Our method is easily
implemented for big-data applications, whereas other methods are limited in this regard.
|
|
|
|
||
|
Sacha Morin *, Robin Legault *, Félix Laliberté, Zsuzsa Bakk , Charles-Édouard Giguère , Roxane de la Sablonnière , Éric Lacourse [Journal] Journal of Statistical Software (JSS), 2025 code / paper |
|
|
Updated July 2026 |